 Sky Blog
Sky Blog
Machines are increasingly making important decisions that have traditionally been made by humans, such as who should get a job interview or who should receive a loan. For valid legal, reputational, and technical reasons, many organizations and regulators do not fully trust machines to make these judgments by themselves. As a result, humans usually remain involved in AI decision making, which is referred to as a “human-in-the-loop.” For example, in the detection of skin cancer, the process may now involve an AI machine reviewing a photograph of a mole and making a preliminary assessment of cancer risk, followed by a dermatologist either confirming or rejecting that determination.
For these kinds of decisions, where human safety is at risk and there is an objectively correct answer (i.e., whether a mole is cancerous or not), human review of AI decisions is appropriate, and indeed, may be required by regulation. But little has been written about exactly when and how humans should review AI decisions, and how that review should be conducted for decisions with no objectively correct answer (e.g., who deserves a job interview). This article is an attempt to fill in some of those gaps by proposing a framework for achieving optimal joint human-machine decision making that goes beyond assuming that human judgment should always prevail over machine decisions.
Regulatory Requirements for Human Review of AI Decisions
Most regulations that address machine decision making require humans to review machine decisions that carry significant risks. For example, Article 22 of the European Union’s General Data Protection Regulation provides that EU citizens should not be subject to “solely automated” decisions that significantly affect them. The European Commission’s proposed AI Act similarly provides that high-risk AI systems should be designed and developed so that they can be effectively overseen by natural persons, including by enabling humans to intervene in or interrupt certain AI operations. In the United States, the Biden Administration’s recently released Blueprint for an AI Bill of Rights (which is not binding but will likely be influential on any future U.S. AI regulations) provides that AI systems should be monitored by humans as a check in the event that an automated system fails or produces an error.
These and other AI regulations require some level of human oversight over autonomous decision making to catch what are referred to as “algorithmic errors,” which are mistakes made by machines. Such errors certainly do occur, but these regulations are flawed to the extent that they imply that whenever a human and a machine make different decisions or reach different conclusions, the machine is necessarily wrong and the human is necessarily right. As discussed below, in many instances, there is no objectively right decision, and resolving the disagreement in favor of the human does not always lead to the optimal result.
In a recent Forbes article on AI ethics and autonomous systems, Lance Eliot provided some alternatives for resolving human-machine disagreements instead of defaulting to a view that the human is always correct:
- The machine’s decision prevails;
- Some predetermined compromise position is adopted;
- Another human is brought into the decision-making process; or
- Another machine is brought into the decision-making process.
Eliot rightly points out that over thousands of years, societies have developed several ways to efficiently resolve human-human disagreements, and, in fact, we often design processes to surface such disagreements in order to foster better overall decision making. Creating a similar system for identifying and resolving human-machine disagreements will be one of the fundamental challenges of AI deployment and regulatory oversight in the next five years. As discussed below, for many AI uses, it makes sense to require a human to review a machine’s decisions and override it when the human disagrees. But for some decisions, that approach will result in more errors, reduced efficiencies, and increased liability risks, and a different dispute resolution framework should be adopted.
Not All Errors Are Equal – False Positives vs. False Negatives
For many decisions, there are two different types of errors – false positives and false negatives — and they may have very different consequences. For example, assume that for every 100 patients, a dermatologist can accurately identify a mole as being cancerous 90% of the time. For the patients who receive an incorrect diagnosis, it would be much better if the doctor’s mistake is wrongly identifying a mole as cancerous when it is not (i.e., a false positive), rather than wrongly identifying a cancerous mole as benign (i.e., a false negative). A false positive may result in an unnecessary biopsy that concludes that the mole is benign, which involves some additional inconvenience and cost. But that is clearly preferable to a false negative (i.e., a missed cancer diagnosis) which can have catastrophic results, including delayed treatment or even untimely death.
Now suppose that a machine that checks photographs of moles for skin cancer is also 90% accurate, but because the machine has been trained very differently from the doctor and does not consider the image in context of other medical information (e.g., family history), the machine makes different mistakes than the doctor. What is the optimal result for patients when the doctor and the machine disagree as to whether a mole is benign or cancerous? Considering the relatively minor cost and inconvenience of a false positive, the optimal result may be that if eitherthe doctor or the machine believes that the mole is cancerous, it gets shaved and sent for a biopsy. So, adding a machine into the decision-making process and treating it as an equal to the doctor increases the total number of errors. But because that decision resolution framework reduces the number of potentially catastrophic errors, the overall decision-making process is improved. If instead, the human’s decision always prevailed, there would be cases where the machine detected cancer, but the human did not, so no biopsy was taken, and the cancer was discovered only later, perhaps with extremely negative implications for the patient caused by the delayed diagnosis. This would obviously be a less desirable outcome, with increased costs, liability risks, and most significantly, patient harm.
Not All Decisions Are Right or Wrong – Sorting vs. Selecting
There are times when machines make mistakes. If a semi-autonomous car wrongly identifies a harvest moon as a red traffic light and slams on the brakes, that is an error, and the human driver should be able to override that incorrect decision. Conversely, if the human driver is heavily intoxicated or has fallen asleep, their his driving decisions are likely wrong and should not prevail.
But many machine decisions do not lend themselves to a binary right/wrong assessment. For example, consider credit and lending decisions. A loan application from a person with a very limited credit history may be rejected by a human banker, but that loan may be accepted by an AI tool that considers non-traditional factors, such as cash flow transactions from peer-to-peer money transfer apps. For these kinds of decisions, it is difficult to characterize either the human or the machine as right or wrong. First, if the loan is rejected, there is no way to know whether it would have been paid off had it been granted, so the denial decision cannot be evaluated as right or wrong. In addition, determining which view should prevail depends on various factors, such as whether the bank is trying to expand its pool of borrowers and whether false positives (i.e., lending to individuals who are likely to default) carry more or less risk than false negatives (i.e., not lending to individuals who are likely to repay their loans in full).
The False Choice of Rankings and the Need for Effective Equivalents
Many AI-based decisions represent binary yes/no choices (e.g., whether to underwrite a loan or whether a mole should be tested for cancer). But some AI systems are used to prioritize among candidates or to allocate limited resources. For example, algorithms are often used to rank job applicants or to prioritize which patients should receive the limited number of organs available for transplant. In these AI sorting systems, applicants are scored and ranked. However, as David Robinson points out in his book, Voices in the Code, it seems arbitrary and unfair to treat one person as a superior candidate for a kidney transplant if an algorithm gave them a score of 9.542, when compared to a person with a nearly identical score of 9.541. This is an example of the precision of the ranking algorithm creating the illusion of a meaningful choice, when in reality, the two candidates are effectively equal, and some other method should be used to select between them.
Humans and Machines Playing to Their Strengths and the Promise of Joint Decision Making
Despite significant effort to use AI to improve the identification of cancer in mammograms or MRIs, these automated screening tools have struggled to make diagnostic gains over human physicians. Doctors reading mammograms reportedly miss between 15% and 35% of breast cancers, but AI tools often underperform doctors. The challenge of AI for mammogram analysis is different from the skin cancer screening discussed above because mammograms have a much higher cost for false positives; a biopsy of breast tissue is more invasive, time-consuming, painful, and costly than shaving a skin mole.
However, a recent study published in The Lancet indicates that a complex joint-decision framework, with doctors and AI tools working together, and checking each other’s decisions, can lead to better results for the review of mammograms – both in terms of reducing false positives (i.e., mammograms wrongly categorized as showing cancer when no cancer is present) and reducing false negatives (i.e., mammograms wrongly categorized as showing no cancer when cancer is present).
According to this study, the suggested optimal workflow involves the machine being trained to sort mammograms into three categories: (1) confident normal, (2) not confident, and (3) confident cancerous:
- Confident Normal: If the machine determines that a mammogram is clearly normal (which is true for most cases), that decision is reviewed by a radiologist who is informed about the machine’s previous decision. If the radiologist disagrees with the machine and believes that cancer may be present, then additional testing or a biopsy is ordered. If a biopsy is conducted and the results are positive, then the machine’s decision is viewed as a false negative and the biopsy results are used to recalibrate the machine.
- Not Confident or Confident Cancerous: If the machine determines that a mammogram is likely cancerous, or the machine is uncertain as to its decision, then that mammogram is referred to a different radiologist, who is not told which of those two decisions the machine made. If the radiologist independently determines that the mammogram is likely cancerous, then a biopsy is ordered. If the radiologist independently determines that the mammogram is normal, then nothing further happens if that mammogram had been previously categorized by the machine as “uncertain.” If, however, the radiologist classifies the mammogram as normal but the machine had previously decided that the mammogram was likely cancerous, then a “safety net” is triggered, and the radiologist is then warned about the inconsistency and asked to review the mammogram again (or another radiologist reviews it). After that second review, the radiologist can either change their initial decision and agree with the machine’s decision to order a biopsy, or overrule the machine and continue to categorize the mammogram as normal.
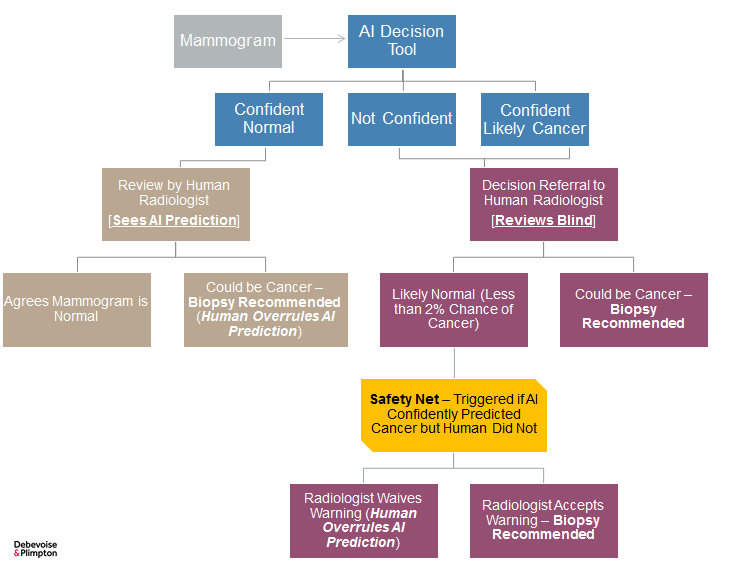
This complicated workflow achieves superior results because it optimizes the elements of decision making where each contributor is superior. The machine is much better at quickly and consistently determining which scans are clearly not interesting. The radiologists are better at determining which potentially interesting scans are actually interesting, but the doctors, being human, are not better all the time. In certain circumstances (e.g., when the doctors are tired, distracted, rushed, etc.), the machine may be better, so a safety net is inserted into the process to capture those situations and thereby optimize the overall decision process. This is a good example as to why the workflow of human-machine decisions needs to be tailored to the particular problem. Here again, having the human decisions always prevail would not achieve the best results. Only through a complex framework, with decision-makers playing to their strengths and covering for each other’s weaknesses (e.g., the machines never getting tired or bored), can results be significantly improved.
Creating a Framework for Resolving Human-Machine Disagreements
Again, much of the regulatory focus on AI decisions is aimed at requiring humans to review certain decisions being made by machines and to correct the machine’s errors. For low-stake decisions that need to be made quickly and in large volume, that is often the right decision framework, even if it is not always the most accurate one. One of the primary benefits of AI is speed, and in designing any human-machine decision framework, one must be careful not to make insignificant gains in optimizing accuracy at the cost of substantial losses in overall efficiency.
But in many circumstances, the decisions being made by AI are significantly impacting people’s lives, and efficiency is therefore not as important as accuracy or rigor. In those cases when humans and machines have a legitimate disagreement, assuming that the human is right and should prevail is not always the best approach. Instead, the optimal results come from an analysis of the particular dispute and the implementation of a resolution framework that is tailored to the particular decision-making process and automated technology.
Below are some examples of how different human-machine decision frameworks may be appropriate depending on the circumstances.
Option #1 – Human in the Loop: The machine reviews a large number of candidates and makes an initial assessment by ranking them, but the actual selection is made by a human
Decision Examples:
- Who should receive an interview for a particular job.
- Who should be admitted to a particular college.
- Which insurance claims should be investigated for potential fraud.
Factors:
- The machine is good at sorting strong candidates for selection from weak ones, but is not as good at selecting the best among a group of strong candidates.
- Significant time is saved by the machine finding the strong candidates from a large pool of weak candidates.
- The final selection decision is very complex, with many intangible factors.
- There is an expectation of human involvement in the final selection decision by the persons who are impacted by that decision.
Option #2 – Human Over the Loop: The machine makes an initial decision without human involvement, which can be quickly overridden by a human if necessary
Decision Examples:
- Whether a credit card purchase was fraudulent and the credit card should be disabled to avoid further fraud.
- Whether a semi-autonomous vehicle should brake to avoid a collision.
Factors:
- The need to make a large number of decisions on an ongoing basis, and in most cases, the decision is to do nothing.
- The decisions need to be made extremely quickly.
- There is a significant risk of harm from even short delays in making the correct decision.
- The decisions are easily reversible and a human can easily intervene after the machine decision has been made.
- There is usually a clear right or wrong decision that humans can quickly ascertain.
Option #3 – Machine Authority: The machine prevails in a disagreement with a human
Decision Examples:
- AI cybersecurity detection tool prevents a human from emailing out a malicious attachment that is likely to spread a computer virus.
- A semi-autonomous delivery truck pulls over and stops if it detects that its human driver has fallen asleep or is severely intoxicated.
Factors:
- Need for quick decisions to prevent significant harm.
- Substantial risks to human safety or property if the human is wrong and much smaller risks if the machine is wrong.
- Possibility that human decision making is impaired.
Option #4 – Human and Machine Equality: If either the human or the machine decides X, then X is done
Decision Examples:
- Deciding whether to send a potentially cancerous mole for a biopsy.
- Which employees should receive an additional security check before gaining computer access to highly confidential company documents.
Factors:
- Both machine and human have high accuracy, but they make different errors.
- The cost of either the machine or the human missing something (i.e., a false negative) is much higher than the cost of either the machine or the human flagging something that turns out not to be an issue (i.e., a false positive).
Option #5 – Hybrid Human-Machine Decisions: Human and machine check each other’s decisions, sometimes without prior knowledge of what the other decided; for high-risk decisions where the human and machine clearly disagree, the human (or another human) is alerted and asked to review the decision again.
Decision Examples:
- Assessing mammograms to decide whether they indicate the presence of cancer and whether a biopsy should be ordered (discussed above).
- Reviewing a large volume of documents before producing them to opposing counsel in a litigation or investigation to decide whether they contain attorney-client privileged communications.
Factors:
- There are significant costs for both false positives and false negatives.
- The important decision is made in very few cases, and most of the cases are not interesting.
- The machine is very good at confidently identifying cases that are not interesting, and that decision can be quickly confirmed by a human, and recalibrated if necessary.
- There are a significant number of cases where the machine is uncertain as to the correct decision.
- The machine is not very good at determining which potentially interesting cases are actually interesting, but the machine can improve with additional training.
- The human is better overall at determining which potentially interesting cases are actually interesting, but the human is not consistently better, and at certain times (when the human is tired, distracted, rushed, etc.), the machine is better.
Conclusion
These examples demonstrate that there are several viable options for resolving disputes between machines and humans. Sometimes, circumstances call for a simple workflow, with human decisions prevailing. In other cases, however, a more complicated framework may be needed because the humans and the machines excel at different aspects of the decision, which do not easily fit together.
In the coming years, efforts to improve people’s lives through the adoption of AI will accelerate. Accordingly, it will become increasingly important for regulators and policy makers to recognize that several options exist to optimize human-machine decision making. Requiring a human to review every significant AI decision, and to always substitute their decision for the machine’s decision if they disagree, may unnecessarily constrain certain innovations and will not yield the best results in many cases. Instead, the law should require AI developers and users to assess and adopt the human-machine dispute-resolution framework that most effectively unlocks the value of the AI by reducing the risks of both human and machine errors, improving efficiencies, and providing appropriate opportunities to challenge or learn from past mistakes. For many cases, that framework will involve human decisions prevailing over machines, but it won’t for all.
This post comes to us from Debevoise & Plimpton LLP. It is based on a post on the firm’s Data Blog, “When Humans and Machines Disagree – The Myth of “AI Errors” and Unlocking the Promise of AI Through Optimal Decision Making,” available here.